

Bạn đang hết message limit quá nhanh mỗi ngày? Hóa đơn API cuối tháng cao hơn dự kiến? Gốc rễ vấn đề thường không phải bạn dùng nhiều — mà là bạn đang tiêu token Claude AI không hiệu quả. Một prompt viết sai có thể tốn gấp 3–5 lần so với prompt viết đúng, cho cùng một kết quả.
Bài này tổng hợp 12 kỹ thuật thực chiến để tiết kiệm token Claude AI — từ cách cài Custom Instructions, tối ưu prompt, dùng Projects, tránh regenerate, đến chọn đúng model. Kèm template copy-paste sẵn cho 4 nhóm người dùng phổ biến nhất.
- Token Claude AI là gì? Tại sao cần tiết kiệm?
- Sai lầm phổ biến: Claude nhảy code/HTML trước khi cần
- Cài Memory & Custom Instructions — dạy 1 lần nhớ mãi
- Kỹ thuật prompt tiết kiệm token
- Dùng Projects để giảm lặp context
- Kỹ thuật “Phân đoạn” — chia nhỏ thay vì yêu cầu 1 lần
- Tránh Regenerate — nút tốn token nhất
- Chọn đúng model cho đúng việc
- Tận dụng Artifacts & Claude.ai Features
- Mẹo cho API Users
- Template Custom Instructions mẫu — copy-paste
- Câu hỏi thường gặp (FAQ)
I. Token Claude AI Là Gì? Tại Sao Cần Tiết Kiệm?
Khi bạn gửi tin nhắn cho Claude AI, văn bản được chia thành các đơn vị nhỏ gọi là token. Khoảng 0.75 từ tiếng Anh = 1 token. Tiếng Việt nhiều ký tự hơn nên tỷ lệ thường khoảng 1.2–1.5 token/từ.
Token được tính cả chiều vào lẫn chiều ra: prompt bạn gửi (input tokens) và phản hồi Claude trả về (output tokens). Hội thoại dài? Claude phải đọc lại toàn bộ lịch sử chat mỗi lần — token tích lũy nhanh hơn bạn nghĩ.
Tại sao cần tiết kiệm token Claude AI?
Với người dùng Claude Pro ($20/tháng): giới hạn message mỗi 5 giờ nghĩa là nếu mỗi message tốn ít token hơn, bạn kéo dài được thời gian dùng trước khi bị rate limit. Với API users: token input/output được tính tiền trực tiếp — Sonnet 3.7 khoảng $3/$15 per million tokens; Haiku $0.8/$4. Tối ưu 50% token = giảm 50% hóa đơn.
Quan trọng: Token không chỉ ảnh hưởng đến chi phí — nó còn quyết định chất lượng phản hồi. Context window càng đầy (hội thoại quá dài, tài liệu quá nhiều) thì Claude càng “quên” thông tin ở đầu. Tiết kiệm token = context sạch hơn = câu trả lời tốt hơn.
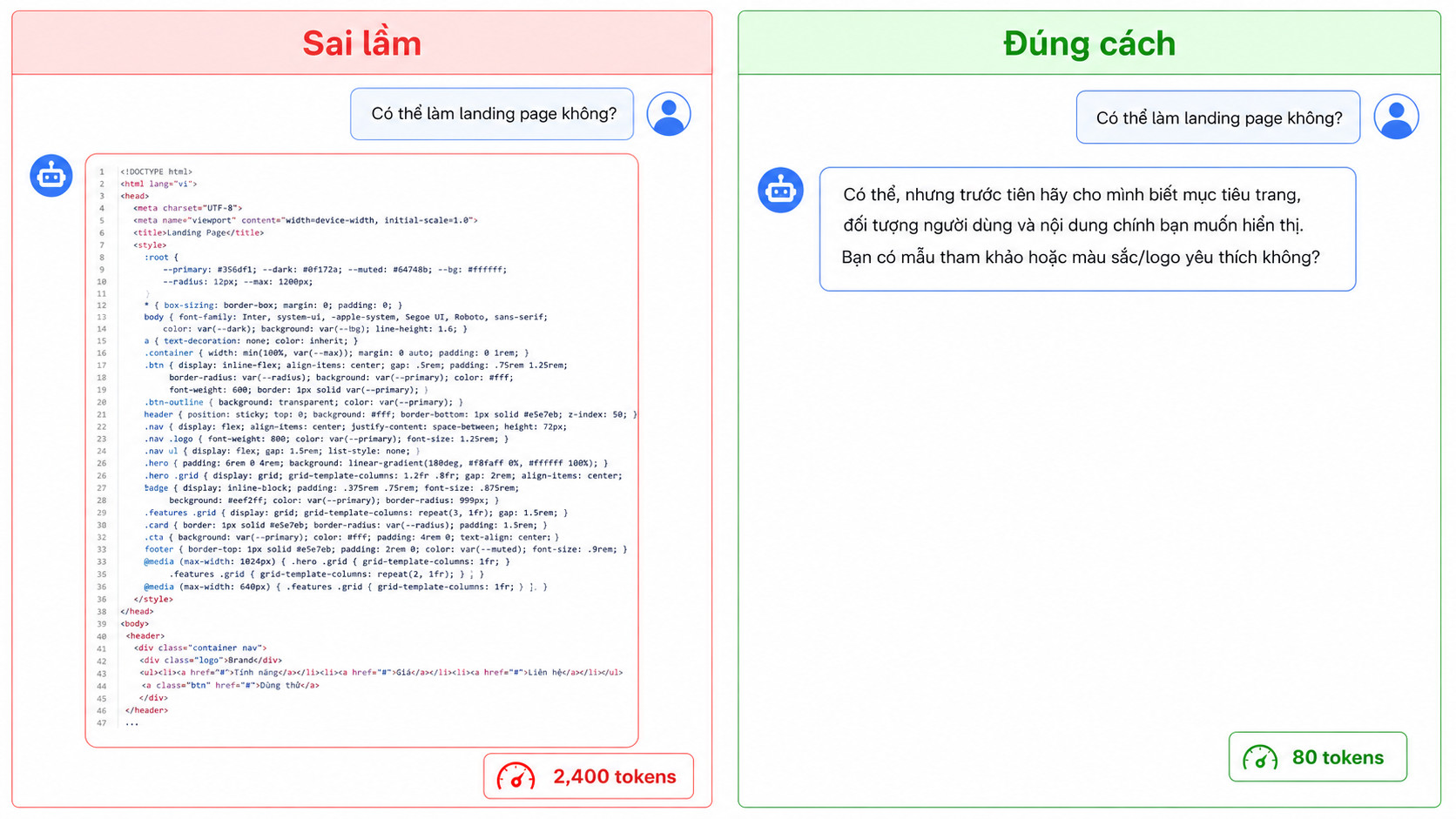
II. Sai Lầm Phổ Biến: Claude Nhảy Code/HTML Trước Khi Cần
Đây là vấn đề người dùng gặp nhiều nhất nhưng ít ai nhận ra: Claude có xu hướng sinh output dài và đầy đủ ngay cả khi bạn chỉ muốn hỏi một câu đơn giản.
Bạn hỏi “Có thể làm landing page bằng Next.js không?” — Claude viết luôn toàn bộ component đầy đủ dù bạn chỉ muốn câu trả lời Có/Không. Kết quả: output dài 300 dòng code = hàng nghìn token lãng phí.
Các tình huống Claude hay tốn token không cần thiết
Tốn token vô ích
- Hỏi thăm dò → Claude viết code đầy đủ ngay
- Hỏi cách làm → Claude làm luôn không hỏi
- Yêu cầu mơ hồ → Claude tự điền giả định, làm lại
- Không giới hạn output → Claude viết 3× cần thiết
- Chat đa mục đích trong 1 hội thoại
Tiết kiệm token
- Thêm “Chỉ trả lời bằng text, chưa cần code”
- Thêm “Hỏi tôi trước khi làm nếu chưa rõ”
- Đặt câu hỏi cụ thể, có đủ constraint ngay
- Thêm “Trả lời trong 100 từ”
- Mỗi hội thoại một chủ đề duy nhất
Giải pháp đơn giản nhất: Thêm vào cuối mọi câu hỏi thăm dò: Chỉ trả lời ngắn gọn, chưa cần viết code/HTML. Một câu thêm này có thể cắt output từ 2000 token xuống còn 100 token.
III. Cài Memory & Custom Instructions — Dạy Claude 1 Lần Nhớ Mãi
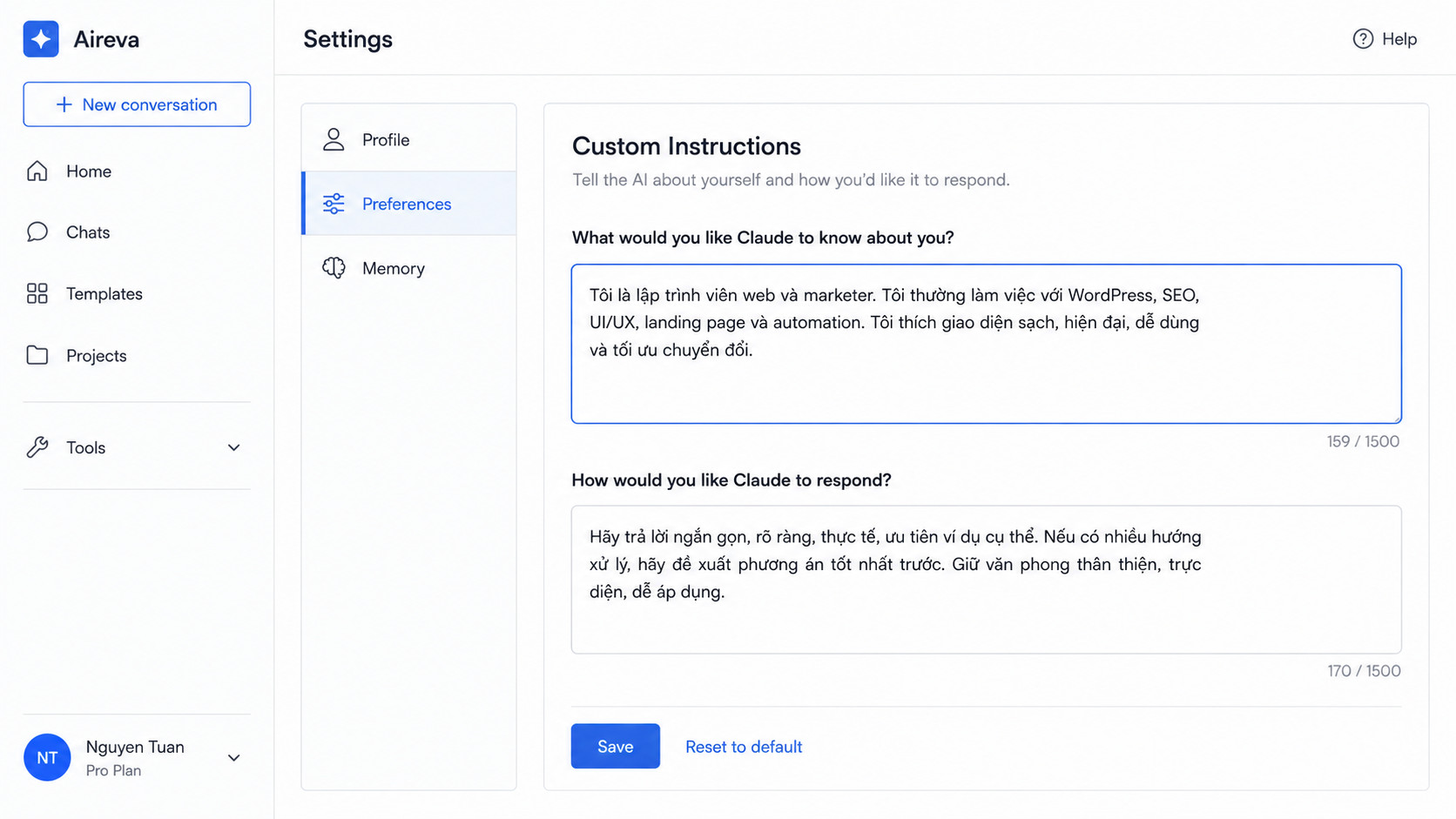
Custom Instructions (Hướng dẫn tùy chỉnh) là tính năng cho phép bạn thiết lập ngữ cảnh, phong cách và quy tắc mà Claude sẽ nhớ xuyên suốt mọi hội thoại. Thay vì paste lại “Tôi là developer, thích code ngắn gọn…” mỗi lần mở chat mới, bạn cài 1 lần là xong.
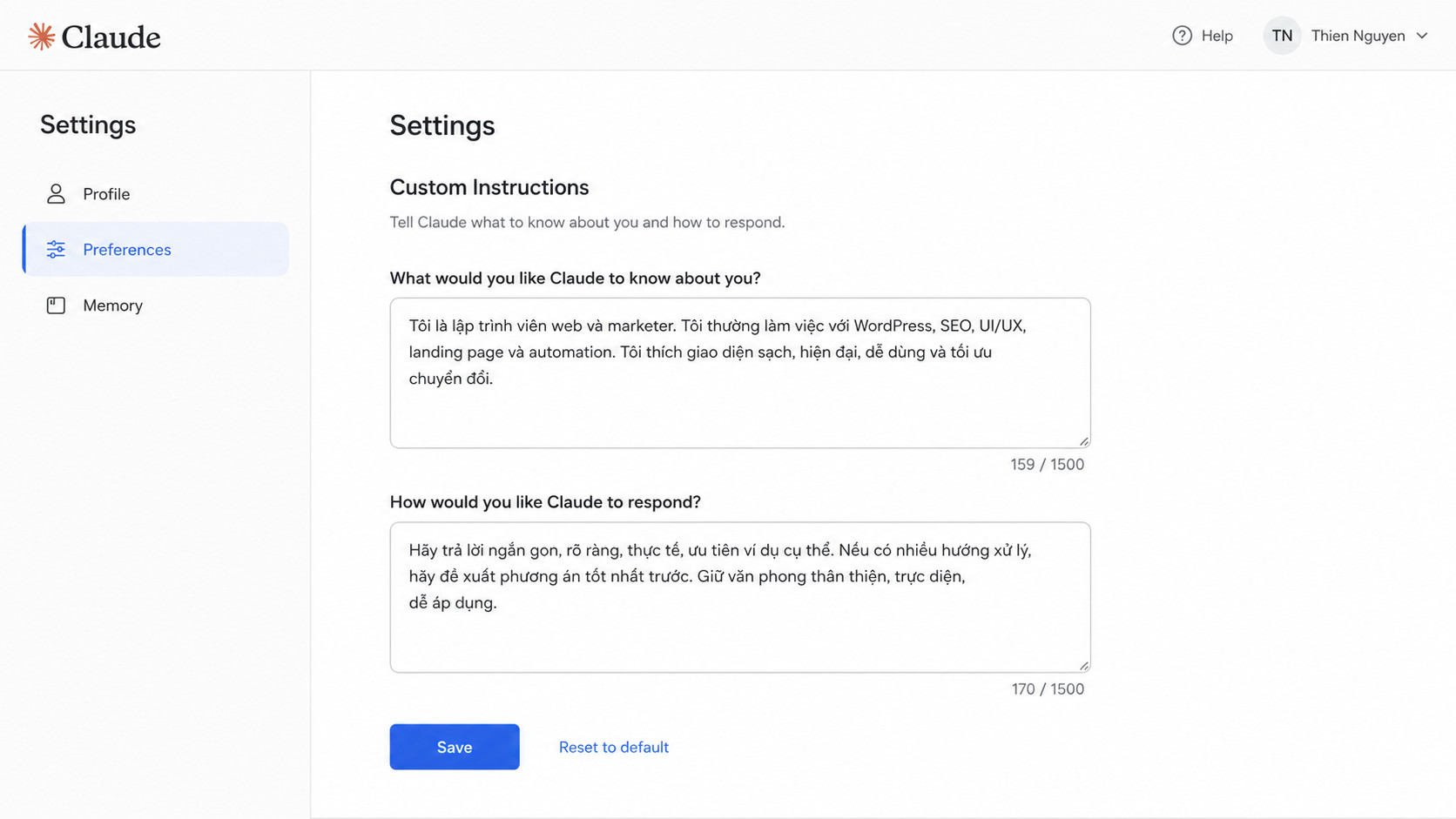
Cách vào Settings để cài Custom Instructions
Mở Settings trên Claude.ai
Đăng nhập vào claude.ai → click vào avatar/tên góc trên bên trái → chọn “Profile” → chọn tab “Preferences”. Hoặc vào thẳng claude.ai/settings.
Tìm mục “Custom Instructions”
Cuộn xuống phần Custom Instructions — có 2 ô: “What would you like Claude to know about you?” (context về bạn) và “How would you like Claude to respond?” (style phản hồi). Điền vào cả hai.
Giới hạn 100–200 từ mỗi ô
Custom Instructions được tính token mỗi cuộc hội thoại. Viết quá dài (500+ từ) phản tác dụng. Mục tiêu: ngắn gọn nhưng đủ để Claude không cần hỏi lại những thứ bạn đã biết.
Bật Memory (nếu có)
Tab “Memory” trong Settings → bật toggle. Claude sẽ tự học thêm từ các hội thoại (nhớ sở thích, dự án đang làm). Kết hợp Memory + Custom Instructions = không bao giờ phải giải thích lại context từ đầu.
Ví dụ mẫu điền Custom Instructions
Ô “What to know about you”:
Tôi là developer PHP/WordPress, dùng WooCommerce và LearnPress. Dự án chính: khoahocre.com (e-learning Việt Nam). Tech stack: WordPress, WPCode, Elementor, MySQL, cPanel. Trình độ: intermediate — hiểu code, không cần giải thích cú pháp cơ bản. Ngôn ngữ ưu tiên: trả lời tiếng Việt, code comment tiếng Anh.
Ô “How to respond”:
- Trả lời ngắn gọn, đúng trọng tâm. Không lặp lại câu hỏi. - Nếu chưa rõ yêu cầu, hỏi 1 câu trước khi làm. - Không tự sinh code/HTML nếu tôi chỉ hỏi khái niệm. - Với code: chỉ viết phần thay đổi, không rewrite toàn bộ file. - Không dùng emoji. Không bắt đầu bằng "Tất nhiên!" hay "Chắc chắn rồi!".
Hiệu quả thực tế: 2 ô Custom Instructions trên tiết kiệm được trung bình 50–150 token/message (không phải paste context mỗi lần) + giảm đáng kể output thừa nhờ rule “hỏi trước khi làm”.
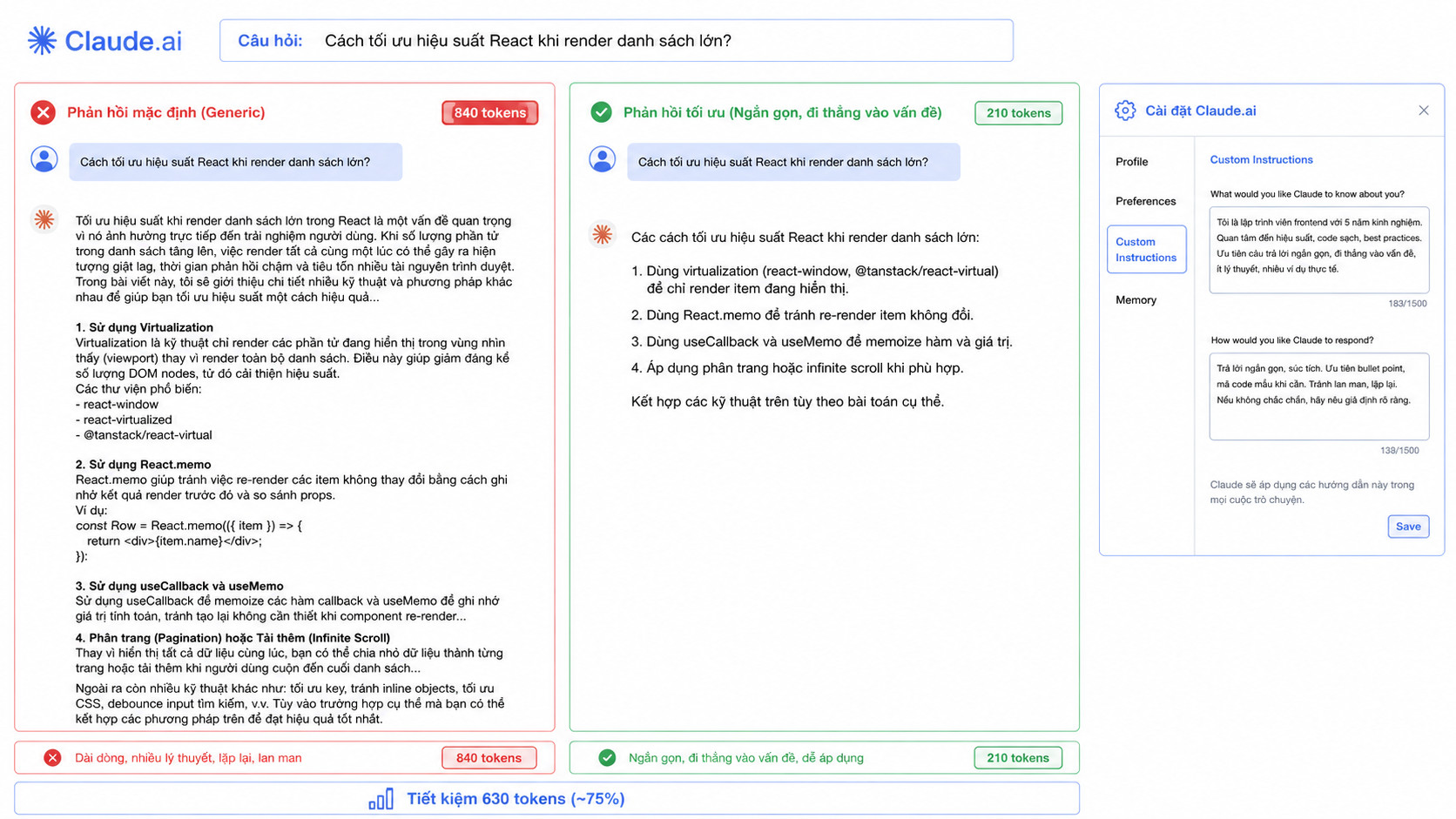
IV. Kỹ Thuật Prompt Tiết Kiệm Token Claude AI
Cách bạn viết prompt là yếu tố đơn lẻ ảnh hưởng lớn nhất đến lượng token tiêu thụ. Không phải prompt dài là tốt, không phải ngắn là tiết kiệm — mà là đủ và chính xác.
So sánh prompt tốn vs tiết kiệm token
Tốn token (~1800 token)
- “Giải thích cho tôi về Next.js và cách nó hoạt động và tại sao nên dùng nó”
- “Viết cho tôi một bài blog về AI”
- “Sửa code này” + paste 500 dòng
- Không có constraint → Claude tự điền
Tiết kiệm (~340 token)
- “Next.js khác React thuần như thế nào? 3 điểm chính, mỗi điểm 1 câu.”
- “Viết intro bài blog AI, 80 từ, tone chuyên nghiệp”
- “Hàm X từ dòng Y đến Z — chỉ sửa logic validate email”
- Chỉ định rõ format + độ dài output
7 constraint giảm token output mạnh nhất
V. Dùng Projects Để Giảm Lặp Context
Projects là tính năng của Claude.ai cho phép bạn tạo không gian làm việc riêng biệt với context được duy trì xuyên suốt nhiều hội thoại. Upload tài liệu, file code, hướng dẫn dự án vào Project — Claude nhớ tất cả mà không cần bạn paste lại.
Không dùng Projects — Lãng phí
- Chat mới → paste lại cả file code mỗi lần
- Nhắc lại “Dự án của tôi là X, dùng Y, làm Z…”
- Paste lại tài liệu reference 10+ lần/ngày
- Mỗi chat tốn 500–2000 token chỉ để thiết lập context
Dùng Projects đúng cách
- Upload file code, schema, docs vào Project 1 lần
- Project Instructions viết context dự án (100 từ)
- Mọi chat trong Project tự nhận context sẵn
- Tiết kiệm 500–2000 token mỗi lần bắt đầu chat
Cách dùng Projects hiệu quả
Tạo Project cho từng dự án lớn
Ví dụ: “khoahocre.com dev”, “Bài blog tháng 5”, “Phân tích dữ liệu Q2”. Mỗi Project là một context riêng biệt — không lẫn lộn.
Upload tài liệu reference vào Project Files
Schema database, style guide, file cấu hình, docs kỹ thuật. Claude đọc khi cần — không tốn token trong mọi message, chỉ khi được truy cập.
Viết Project Instructions ngắn gọn
Phần instructions được nạp vào mỗi hội thoại — giữ dưới 150 từ. Tập trung vào: mục tiêu project, tech stack, naming convention, style guide tóm tắt.
Bắt đầu chat mới thay vì kéo dài hội thoại cũ
Hội thoại dài = tốn token đọc lại lịch sử. Trong cùng Project, bắt đầu chat mới cho task mới — context dự án vẫn giữ nguyên, nhưng không mang theo rác từ hội thoại trước.
VI. Kỹ Thuật “Phân Đoạn” — Chia Nhỏ Thay Vì Yêu Cầu 1 Lần
Trực giác thường mách “yêu cầu tất cả 1 lần sẽ tiết kiệm hơn”. Thực ra ngược lại: prompt quá lớn → Claude phải suy nghĩ nhiều hơn → output dài hơn → token nhiều hơn. Chia nhỏ task thường tiết kiệm token tổng cộng hơn.
Sai — Yêu cầu 1 lần quá nhiều
- “Viết landing page đầy đủ: hero, features, pricing, testimonial, FAQ, footer, responsive, dark mode, animation, SEO…”
- Kết quả: Claude đoán mò giả định → ra kết quả sai → phải làm lại → tổng token x3
Đúng — Phân đoạn từng bước
- Bước 1: “Tạo cấu trúc HTML skeleton, chưa cần CSS”
- Bước 2: “Thêm CSS cho hero section, màu #356df1”
- Bước 3: “Thêm responsive breakpoint mobile”
- Kết quả: Kiểm soát được, ít sai hơn, token ít hơn
Quy tắc chia đoạn hiệu quả
- 1 prompt = 1 output type: Không vừa yêu cầu “phân tích” vừa “viết code” vừa “tóm tắt” trong cùng 1 prompt.
- Review trước khi tiếp tục: Sau mỗi bước, đọc kết quả và approve/yêu cầu chỉnh sửa nhỏ trước khi chuyển bước tiếp theo.
- Dùng “Tiếp tục từ đây”: Nếu cần Claude viết thêm, dùng
Tiếp tục từ đây: [paste đoạn cuối]thay vì bắt đầu lại toàn bộ.
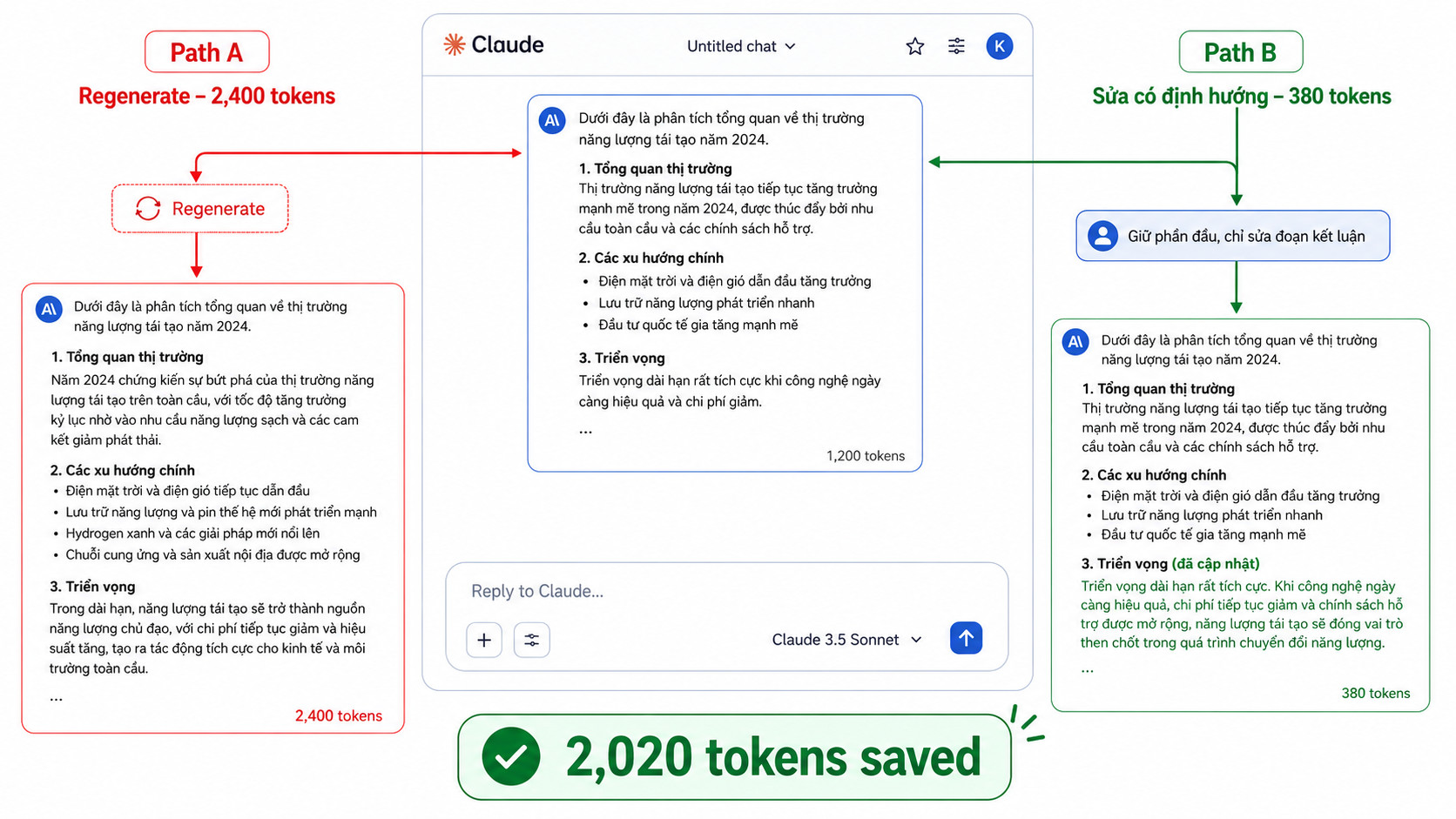
VII. Tránh Regenerate — Nút Tốn Token Nhất
Nút Regenerate (hay “Try again”) là thứ tốn token vô ích nhất trên Claude.ai. Mỗi lần nhấn, Claude phải đọc lại toàn bộ hội thoại + sinh output mới từ đầu — gần như gấp đôi token so với yêu cầu chỉnh sửa có định hướng.
Thay thế Regenerate bằng 3 cách này
Edit prompt cũ (nút bút chì)
Hover vào message của bạn → click icon bút chì → sửa trực tiếp prompt → gửi lại. Claude chỉ tính token từ điểm đó trở đi, không tính lại lịch sử trước. Đây là cách tiết kiệm token nhất khi prompt ban đầu bị thiếu thông tin.
Chỉ ra phần cần sửa trong follow-up
Thay vì regenerate toàn bộ, gửi message tiếp: “Giữ nguyên phần [X], chỉ sửa [Y] vì [lý do cụ thể].” Claude chỉ xử lý phần thay đổi — token ít hơn 5–10 lần.
Dùng “Sửa đoạn này thành…”
Với văn bản: copy đoạn cần sửa → paste vào follow-up message → “Sửa đoạn này: [đoạn cần sửa] → thành: [yêu cầu thay đổi].” Claude không cần đọc lại ngữ cảnh, chỉ tập trung vào đoạn đó.
Tệ nhất: Nhấn Regenerate nhiều lần vì “chưa ưng”. Mỗi lần regenerate tốn token tương đương một prompt mới. Thay vào đó, hãy dành 10 giây viết rõ mình không hài lòng chỗ nào — luôn hiệu quả và rẻ hơn.
VIII. Chọn Đúng Model Cho Đúng Việc
Việc chọn đúng model Claude là cách tiết kiệm token Claude AI (và tiền với API) nhanh nhất mà ít ai để ý. Dùng Opus cho task đơn giản = lãng phí gấp 5–15 lần so với dùng Haiku.
| Model | Tốc độ | API Cost (input/output) | Dùng khi nào | Tránh khi nào |
|---|---|---|---|---|
| Claude Haiku | Rất nhanh | $0.8 / $4 per M token | Tóm tắt ngắn, phân loại, Q&A đơn giản, extract data, dịch thuật, fill template | Reasoning phức tạp, code khó, phân tích sâu |
| Claude Sonnet | Nhanh | $3 / $15 per M token | 90% tác vụ hàng ngày: viết content, code thông thường, phân tích, brainstorm, debug | Task cực kỳ đơn giản (dùng Haiku), task đòi hỏi suy luận tối đa (dùng Opus) |
| Claude Opus | Chậm hơn | $15 / $75 per M token | Suy luận phức tạp nhiều bước, phân tích tài liệu dài, code architecture, research chuyên sâu | Task thông thường — tốn tiền không cần thiết |
Quy tắc chọn model nhanh
- “Có phải suy nghĩ không?” → Không: Haiku. Có vừa phải: Sonnet. Cần tư duy phức tạp: Opus.
- Output dài hay ngắn? → Ngắn (<500 từ): Haiku ổn. Dài hoặc phức tạp: Sonnet.
- Có phải code không? → Bug đơn giản, snippet nhỏ: Haiku/Sonnet. Architecture, review hệ thống: Opus.
Thực tế: Chuyển 70% task sang Haiku và 25% sang Sonnet (chỉ 5% thực sự cần Opus) có thể giảm hóa đơn API xuống 70–80% mà chất lượng output hầu như không thay đổi với tác vụ đơn giản.
IX. Tận Dụng Artifacts & Claude.ai Features
Artifacts là panel bên phải trong Claude.ai hiển thị code, HTML, document riêng biệt. Thay vì chỉnh sửa trong chat (tốn nhiều token), bạn có thể tương tác trực tiếp với artifact để tiết kiệm đáng kể.
Edit trực tiếp trong Artifact
Click vào text trong artifact → sửa trực tiếp không cần chat. Thay đổi nhỏ không tốn token nào.
Nút “Continue” thay vì chat mới
Khi artifact bị cắt giữa chừng, dùng “Continue” — Claude tiếp tục từ điểm dừng, không tính lại từ đầu.
Prompt caching (API)
Với API: bật prompt caching cho system prompt dài. Cache giảm chi phí input token lặp lại 90%.
Cancel streaming sớm
Nếu Claude đang đi sai hướng, cancel ngay (nút Stop) — token output chưa sinh ra sẽ không bị tính.
Reply to specific message
Trả lời trực tiếp một message cụ thể giúp Claude focus context hẹp hơn, không đọc lại toàn bộ hội thoại.
Chat ngắn, Projects dài
Dùng hội thoại ngắn cho task nhỏ. Hội thoại dài nhiều ngày tích lũy token rất lớn dù bạn chỉ hỏi 1 câu.
X. Mẹo Cho API Users — Tối Ưu Từng Cent
Nếu bạn dùng Claude qua API, token ảnh hưởng trực tiếp đến hóa đơn. Đây là các kỹ thuật tối ưu quan trọng nhất:
1. System prompt gọn — mỗi token system prompt tính cho mọi request
// Quá dài, giải thích thừa You are an extremely helpful, knowledgeable, and friendly AI assistant who specializes in answering questions about technology, programming, and software development. You always provide detailed and comprehensive answers. You are patient and understanding. You never refuse to help...
Tech support assistant. Concise answers. Ask clarifying questions
when requirements are ambiguous. Code snippets in markdown.2. Bật Prompt Caching cho system prompt dài
messages = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
system=[{
"type": "text",
"text": long_system_prompt,
"cache_control": {"type": "ephemeral"} # Cache này!
}],
messages=conversation_history
)
# Cache hit = giảm 90% chi phí input token cho system prompt3. Luôn đặt max_tokens hợp lý
# Tóm tắt ngắn — không cần 4096 response = client.messages.create( model="claude-haiku-4-5", max_tokens=256, # Đủ cho summary ngắn messages=[...] ) # Code generation — cần nhiều hơn response = client.messages.create( model="claude-sonnet-4-5", max_tokens=2048, # Đủ cho function vừa messages=[...] )
4. Streaming + cancel sớm
Bật streaming (stream=True) và implement logic để cancel khi output đã đủ — ví dụ khi detect closing tag hoặc end signal. Token chưa generate không tính tiền.
Quick win cho API users: Chuyển tất cả pipeline summarization, classification, extraction sang Haiku. Chỉ dùng Sonnet cho generation và complex reasoning. Bước này đơn giản nhất và tiết kiệm nhiều nhất — thường giảm 60–70% tổng chi phí.
XI. Template Custom Instructions Mẫu — Copy-Paste Ngay
4 template dưới đây được thiết kế để tiết kiệm token Claude AI tối đa: ngắn gọn, đủ context, chặn output thừa. Copy vào Settings → Custom Instructions, chỉnh tên/ngành cho phù hợp.
Template 1 — Developer / Lập trình viên
## CONTEXT Stack: [PHP/WordPress / Node.js / Python — điền của bạn] Project: [tên dự án, mô tả 1 dòng] Level: Senior — hiểu cú pháp, không cần giải thích cơ bản. OS: [Mac/Linux/Windows] ## RESPONSE RULES - Trả lời tiếng Việt, code comment tiếng Anh. - Không sinh code nếu tôi chỉ hỏi khái niệm. - Code sửa đổi: chỉ show phần thay đổi, dùng "// ... existing code ..." - Nếu yêu cầu mơ hồ: hỏi 1 câu cụ thể trước khi làm. - Không lặp lại câu hỏi của tôi trong phản hồi. - Không có đoạn intro "Tất nhiên, để..." hay "Chào bạn..."
Template 2 — Content Writer / Viết nội dung
## CONTEXT Tôi viết content cho [website / blog / mạng xã hội — điền]. Ngành: [lĩnh vực của bạn]. Audience: [đối tượng đọc]. Giọng văn mong muốn: [chuyên nghiệp / thân thiện / cá nhân]. ## RESPONSE RULES - Viết trực tiếp vào nội dung, không có "Đây là bài viết của bạn:..." - Không tự thêm section nếu tôi không yêu cầu. - Khi tôi nói "outline": chỉ trả về tiêu đề các mục, không viết nội dung. - Format: [markdown / plain text — chọn 1]. - Độ dài: theo yêu cầu. Nếu không nói, mặc định 150–200 từ. - Không dùng emoji trừ khi tôi yêu cầu.
Template 3 — Văn phòng / Office Worker
## CONTEXT Tôi làm [vị trí] tại [công ty/ngành]. Hay dùng Claude để: soạn email, tóm tắt tài liệu, phân tích số liệu. Ngôn ngữ: tiếng Việt chính, có thể mix tiếng Anh thuật ngữ. ## RESPONSE RULES - Email/văn bản: viết thẳng vào nội dung, không cần giải thích cách viết. - Tóm tắt: bullet points, tối đa 5 điểm trừ khi yêu cầu khác. - Phân tích: kết luận trước, chi tiết sau. - Không đề xuất thêm dịch vụ hay bước tiếp theo nếu không được hỏi. - Trả lời ngắn nhất có thể mà vẫn đủ thông tin.
Template 4 — Student / Sinh viên đang học
## CONTEXT Tôi là sinh viên năm [1-4], ngành [ngành học]. Đang học/ôn: [môn học / kỳ thi hiện tại]. Mục tiêu: hiểu khái niệm, không chỉ copy đáp án. ## RESPONSE RULES - Giải thích bằng ví dụ thực tế, dễ hình dung. - Nếu tôi hỏi bài tập: hỏi tôi thử trước, sau đó hướng dẫn. - Độ dài: đủ hiểu, không quá dài — max 200 từ trừ khi tôi hỏi thêm. - Có thể dùng analogy (so sánh) để giải thích khái niệm khó. - Khi tôi hiểu rồi muốn tóm tắt: dùng format bảng hoặc bullet ngắn.
XII. Câu Hỏi Thường Gặp
Token Claude AI là gì?
Token là đơn vị xử lý văn bản của Claude — khoảng 0.75 từ tiếng Anh hoặc 1.2–1.5 token/từ tiếng Việt. Mỗi lần chat, cả prompt bạn gửi và phản hồi Claude đều tính token. Hội thoại dài? Claude đọc lại toàn bộ lịch sử mỗi lần — token tích lũy nhanh.
Claude Pro mỗi tháng có bao nhiêu token?
Claude Pro không giới hạn theo số token mà theo số message mỗi 5 giờ — khoảng 45 message với Sonnet, ít hơn với Opus. Tiết kiệm token = mỗi message làm được nhiều hơn = dùng lâu hơn trong khung giờ đó.
Custom Instructions có giúp tiết kiệm token không?
Có, nhưng cần cân bằng. Custom Instructions tính vào mỗi hội thoại — viết quá dài (500+ từ) lại phản tác dụng. Giữ dưới 200 từ: đủ để Claude không hỏi lại context thường xuyên, nhưng không quá nặng mỗi lần load.
Nên dùng Claude Haiku hay Sonnet để tiết kiệm?
Haiku: tóm tắt, phân loại, Q&A đơn giản, translation, fill template — rẻ hơn ~4 lần. Sonnet: 90% tác vụ thông thường — viết, code, phân tích. Opus: chỉ khi cần suy luận phức tạp thực sự. Chuyển pipeline đơn giản sang Haiku thường giảm chi phí API 60–70%.
Prompt dài hay ngắn tốt hơn?
Không phải ngắn nhất mà là đủ nhất. Prompt thiếu context → Claude đoán sai → làm lại = tốn thêm token. Prompt tốt: đủ context + đủ constraint (format, độ dài output, scope) — thường 50–150 từ là tối ưu cho phần lớn tác vụ.
Cách tránh Claude regenerate tốn token?
3 cách thay thế Regenerate: (1) Edit prompt cũ bằng icon bút chì — tiết kiệm nhất; (2) Follow-up cụ thể: “Giữ X, chỉ sửa Y vì Z”; (3) Copy đoạn cần sửa rồi paste vào follow-up “Sửa đoạn này thành…”. Mỗi lần Regenerate tốn gần gấp đôi token so với chỉnh sửa có định hướng.
Tóm lại: Để tiết kiệm token Claude AI hiệu quả, bắt đầu với 3 việc ngay hôm nay: (1) Cài Custom Instructions theo template phù hợp; (2) Thêm constraint độ dài vào mọi prompt; (3) Dừng nhấn Regenerate — thay bằng follow-up cụ thể. Ba thay đổi nhỏ này thường cắt được 50–60% token tiêu thụ hàng ngày.
Bài viết mang tính giáo dục, cập nhật tháng 5/2026. Giá token API có thể thay đổi — kiểm tra tại anthropic.com/pricing. KhoaHocRe.com © 2026




